- DeepSeek-OCR comprime y transfiere de forma eficiente el contenido visual a modelos LLM, preservando contexto y estructura.
- Ofrece modos adaptativos de resolución, integración avanzada con grounding y soporta prompts personalizables para diferentes salidas.
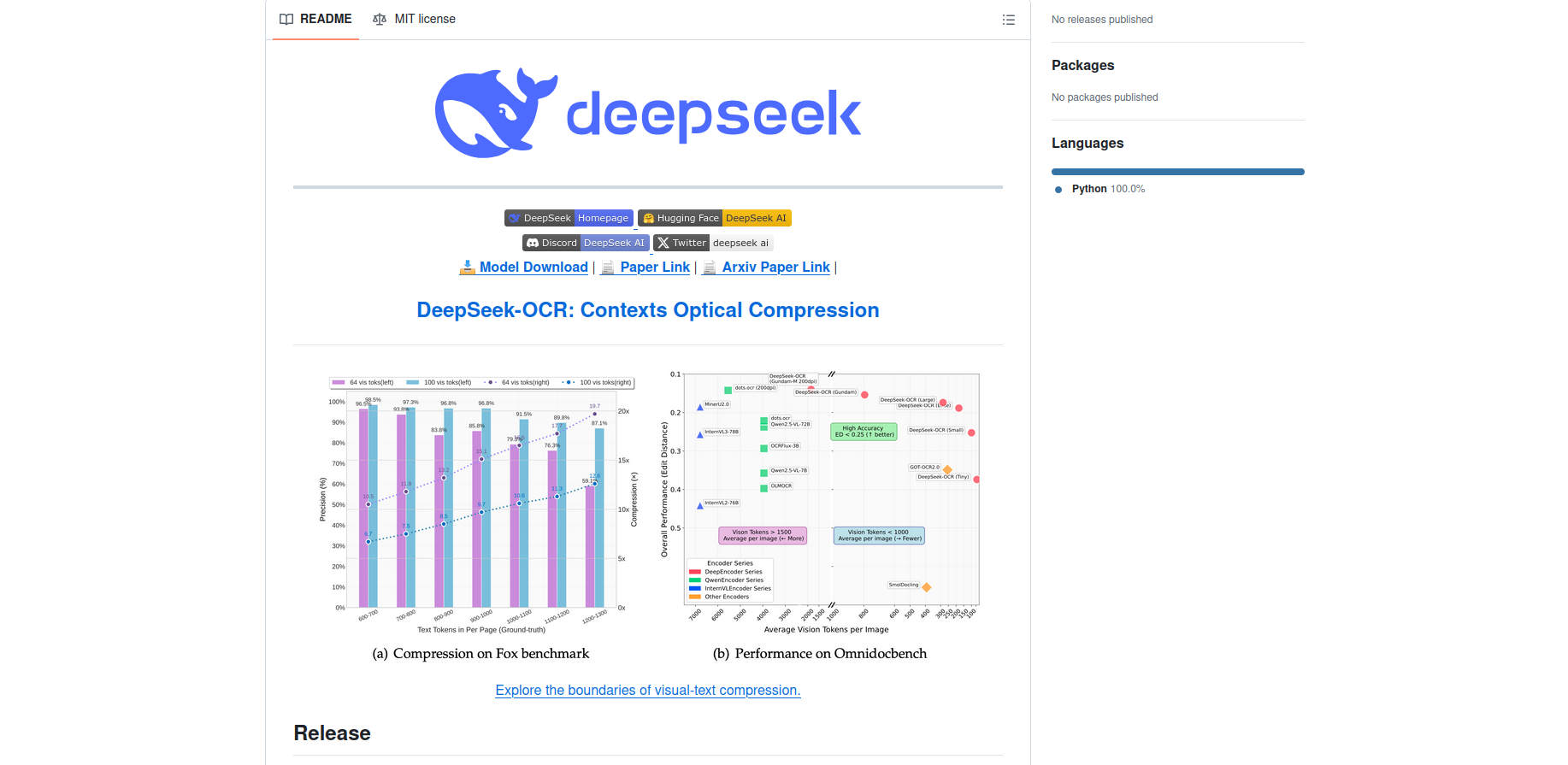
- Supera en benchmarks a los OCR tradicionales en velocidad, compresión y fidelidad, demostrando gran escalabilidad y aplicaciones prácticas.
La irrupción de DeepSeek-OCR en el mundo de la inteligencia artificial aplicada al reconocimiento óptico de caracteres (OCR) está generando un verdadero revuelo en la comunidad tecnológica. Este sistema, nacido bajo el paraguas de DeepSeek-AI, no solo redefine los estándares de precisión y eficiencia en la transcripción de texto desde imágenes, sino que introduce una revolución conceptual: la compresión óptica de contextos. Esta innovación permite transformar datos visuales complejos en representaciones textuales compactas, optimizadas para trabajar con grandes modelos de lenguaje. Para quienes buscan entender en profundidad qué es DeepSeek-OCR, cómo funciona y qué supone para el futuro del procesamiento visual-texto, este artículo se convertirá en la guía de referencia definitiva.
En una época donde el volumen de información visual crece a un ritmo vertiginoso, las soluciones OCR convencionales empiezan a mostrar sus límites. DeepSeek-OCR no solo extrae texto: comprime y estructura los datos visuales, permitiendo una integración inédita con modelos LLM y abriendo nuevas posibilidades para la gestión eficiente de documentos, análisis de imágenes, automatización y accesibilidad. A continuación, se exploran los fundamentos técnicos, los modos de uso, las diferencias clave respecto a otros sistemas y los pasos prácticos para sacarle el máximo partido.
Índice
- 1 ¿Qué es DeepSeek-OCR y qué lo hace diferente?
- 2 Fundamentos técnicos de la compresión óptica contextual
- 3 Modos de resolución y flexibilidad para cada caso de uso
- 4 Diferencias clave respecto a los OCR tradicionales
- 5 Características avanzadas de DeepSeek-OCR
- 6 Rendimiento y benchmarks: métricas que marcan la diferencia
- 7 Comparativa con otros sistemas OCR de referencia
- 8 Instalación y primeros pasos: guía práctica
- 9 Ejemplo de uso y prompts recomendados
- 10 Context Optical Compression: Un nuevo paradigma para los LLMs
- 11 Desafíos técnicos y respuesta de la comunidad
- 12 Impacto y aplicaciones prácticas
- 13 Perspectivas de futuro y desarrollo abierto
¿Qué es DeepSeek-OCR y qué lo hace diferente?
DeepSeek-OCR es un modelo avanzado de reconocimiento óptico de caracteres centrado en la compresión contextual óptica. Desarrollado por el equipo de DeepSeek-AI, su lanzamiento en octubre de 2025 ha supuesto un salto de calidad frente a las metodologías tradicionales. No se trata solo de transcribir caracteres de una imagen a texto: su principal avance radica en cómo condensa la información visual. Utiliza técnicas de compresión que permiten representar el contenido de una imagen (ya sean documentos, gráficos o diagramas) en una cantidad mínima de tokens, especialmente optimizados para su procesamiento posterior en modelos de lenguaje de gran tamaño (LLM).
Este proceso de compresión óptica de contextos implica que los sistemas LLM ya no tienen que batallar con ingentes cantidades de tokens textuales generados por una imagen compleja: DeepSeek-OCR codifica los datos en bloques comprimidos, manteniendo detalles esenciales y relaciones espaciales, al tiempo que reduce drásticamente la carga computacional. Como resultado, es posible procesar imágenes de alta resolución con un consumo de recursos mucho menor, manteniendo además la fidelidad del contenido original, su estructura, y detalles contextuales como la ubicación y formato de cada elemento.
Fundamentos técnicos de la compresión óptica contextual
La compresión óptica contextual es la piedra angular de DeepSeek-OCR. La idea es aprovechar la alta redundancia y riqueza visual de los documentos para generar representaciones latentes que sean mucho más compactas que la simple transcripción textual. En vez de transformar cada palabra visible en una cadena de texto, el sistema crea «fotografías» comprimidas del contenido, que pueden contener texto, estructura, diagramas y relaciones espaciales.
Este mecanismo se apoya en un codificador visual integrado con el modelo de lenguaje. El proceso habitual sería el siguiente:
- El codificador analiza la imagen en diferentes resoluciones.
- Identifica y extrae los elementos clave: texto, títulos, diagramas, relaciones espaciales.
- Genera embeddings o representaciones comprimidas adaptadas a cada caso de uso.
- Los embeddings se fusionan con los prompts de texto para un procesamiento unificado en el LLM, minimizando la longitud total del contexto.
Este diseño reduce la latencia y el coste computacional, ya que se procesan menos tokens y se evita la redundancia habitual cuando el texto se transcribe sin considerar estructura ni contexto visual.
Modos de resolución y flexibilidad para cada caso de uso
DeepSeek-OCR no es un sistema de «talla única». Para adaptarse a diferentes necesidades y recursos disponibles, el modelo ofrece varios modos de resolución, cada uno con una carga de tokens específica:
- Miniatura: 512×512 píxeles, genera 64 tokens. Ideal para vistas previas rápidas.
- Pequeño: 640×640 píxeles, genera 100 tokens. Perfecto para dispositivos con pocos recursos.
- Base: 1024×1024 píxeles, 256 tokens. El punto de equilibrio para la mayoría de aplicaciones.
- Grande: 1280×1280 píxeles, 400 tokens. Permite extraer el máximo detalle manteniendo un consumo de memoria ajustado (por ejemplo, 400 tokens para imágenes muy densas donde otros sistemas exigirían mucho más).
- Gundam (dinámico): combina segmentos de n×640×640 con una vista general de 1024×1024. Especialmente útil para documentos de ultra alta resolución, planos o libros escaneados.
La elección del modo depende de la tarea: desde la automatización documental hasta la descripción de imágenes para accesibilidad. Por ejemplo, en aplicaciones que requieren rapidez y no necesitan todos los detalles del diseño, el modo miniatura puede ser suficiente; para extraer información estructurada de un contrato o analizar un plano arquitectónico, mejor optar por los modos base o grande.
Diferencias clave respecto a los OCR tradicionales
DeepSeek-OCR desafía los límites de sistemas como Tesseract o PaddleOCR gracias a su uso de aprendizaje profundo y arquitectura focalizada en LLM. Mientras que los sistemas clásicos suelen basarse en patrones fijos y motores de reglas que extraen el texto «a secas», DeepSeek-OCR:
- Preserva estructuras complejas como tablas, listas, y títulos.
- Puede incluir información de ubicación mediante etiquetas especiales tipo
<|ref|>xxxx<|/ref|>, útil para anotaciones o consultas espaciales. - Soporta extracción multilingüe, texto manuscrito y manejo de distorsiones en las imágenes.
- Genera salidas adaptadas: texto plano, markdown, texto con cajas delimitadoras (para segmentación avanzada), entre otros.
DeepSeek-OCR convierte imágenes en modelos de datos enriquecidos, preparados para aplicaciones modernas de IA: desde la indexación automática, pasando por la consulta visual, hasta la integración directa en asistentes LLM.
Características avanzadas de DeepSeek-OCR
El modelo ofrece funcionalidades exclusivas para profesionales y desarrolladores que buscan la máxima flexibilidad y rendimiento:
- Integración con frameworks punteros como vLLM y Transformers, lo que agiliza la inferencia y facilita el procesamiento por lotes.
- Capacidades de grounding para referencias espaciales precisas, mejorando la utilidad en entornos de realidad aumentada y edición interactiva de documentos.
- Conversión automática a formato markdown, ideal para digitalización documental en la nube.
- Procesamiento y análisis de figuras: extracción de descripciones y datos de gráficos o diagramas complejos.
- Descripción general de imágenes, generando subtítulos y anotaciones útiles para accesibilidad y búsqueda inteligente.
- Procesamiento concurrente de PDF y grandes volúmenes de imágenes, con benchmarks que superan los 2.500 tokens por segundo en GPUs de gama alta como la A100-40G.
- Prompts personalizables que permiten seleccionar el tipo de salida deseada, optimizando entre velocidad y nivel de detalle.
Rendimiento y benchmarks: métricas que marcan la diferencia
Uno de los aspectos más llamativos de DeepSeek-OCR es su eficiencia en la compresión y la velocidad de procesamiento. En pruebas sobre GPUs profesionales (A100-40G), alcanza tasas de hasta 2.500 tokens por segundo en la extracción de texto de PDF. Además, la arquitectura permite:
- Reducir a la mitad la cantidad habitual de tokens sin perder precisión, manteniendo un 95% de acierto en tareas de extracción textual, según evaluaciones internas.
- Producción de archivos markdown listos para ser integrados en flujos automáticos de digitalización.
Las comparativas con benchmarks reconocidos como Fox y OmniDocBench sitúan a DeepSeek-OCR en el podio tanto en retención de detalles, preservación del layout como en velocidad general.
Comparativa con otros sistemas OCR de referencia
¿Qué gana el usuario al elegir DeepSeek-OCR frente a alternativas como PaddleOCR, GOT-OCR2.0 o MinerU?
- PaddleOCR: Rápido, pero menos eficiente en compresión de datos para LLM. DeepSeek-OCR consigue mejores ratios cuando la prioridad es minimizar tokens.
- GOT-OCR2.0: Buen análisis visual, aunque no incluye modos dinámicos avanzados como el «Gundam» de DeepSeek-OCR, clave para documentos voluminosos.
- MinerU: Potente en minería de datos, pero sin capacidades avanzadas de grounding para una referencia espacial fina.
- Vary: Modelo inspirador, aunque DeepSeek-OCR lleva más lejos la integración con LLM y la adaptabilidad de resolución.
En definitiva, DeepSeek-OCR se distingue por su equilibrio entre compresión, detalle y facilidad de integración, liderando en tareas donde la eficiencia y el contexto visual son cruciales.
Instalación y primeros pasos: guía práctica
Configurar DeepSeek-OCR requiere familiaridad con entornos Python, CUDA y los frameworks de IA más usados. A continuación, se recogen los pasos esenciales para tenerlo operativo:
- Asegurarse de contar con CUDA 11.8 y la versión recomendada de PyTorch (por ejemplo, Torch 2.6.0).
- Clonar el repositorio oficial: git clone https://github.com/deepseek-ai/DeepSeek-OCR.git.
- Crear un entorno virtual (por ejemplo, con Conda):
conda create -n deepseek-ocr python=3.12.9 -y - Activar el entorno:
conda activate deepseek-ocr - Instalar PyTorch y bibliotecas relacionadas:
pip install torch2.6.0 torchvision0.21.0 torchaudio==2.6.0 –index-url https://download.pytorch.org/whl/cu118 - Instalar vLLM de la versión recomendada (puede ser necesario usar el wheel adecuado para la GPU):
pip install vllm-0.8.5+cu118-cp38-abi3-manylinux1_x86_64.whl - Instalar los requisitos del proyecto:
pip install -r requirements.txt - Agregar flash-attention:
pip install flash-attn==2.7.3 –no-build-isolation
Es importante comprobar la compatibilidad entre vLLM y Transformers: según la documentación, algunos errores pueden aparecer pero se ignoran en la práctica.
Ejemplo de uso y prompts recomendados
Una de las ventajas de DeepSeek-OCR es la posibilidad de ajustar el tipo de salida a las necesidades del usuario mediante diferentes prompts. Según las pruebas y documentación, estos son algunos de los prompts más efectivos y versátiles:
"<image>\n<|grounding|>Convert the document to markdown.": Para extraer texto y estructura en formato markdown, ideal para digitalización y preservación de layouts."<image>\n<|grounding|>OCR this image.": Extracción general de texto, buena velocidad y precisión."<image>\nFree OCR.": OCR rápido y sin estructura, para casos donde únicamente interesa el texto plano.
La gestión de prompts permite afinar el equilibrio entre velocidad, calidad del texto, retención de estructura y obtención de coordenadas de los elementos. Un ejemplo típico de uso programático sería integrarlo mediante HuggingFace Transformers, siguiendo los ejemplos de la página oficial del modelo.
Context Optical Compression: Un nuevo paradigma para los LLMs
El principal avance conceptual del modelo es el enfoque de «context optical compression». En lugar de limitarse a almacenar grandes cantidades de texto, DeepSeek-OCR crea «fotografías» comprimidas de fragmentos de contexto, adaptando el nivel de detalle en función de la antigüedad o relevancia del contexto. Este mecanismo, con reminiscencias a la memoria humana, supone un enorme ahorro de memoria y permite trabajar con historiales de conversación o documentos de gran tamaño sin sacrificar velocidad ni precisión.
Por ejemplo, en flujos de trabajo que implican grandes chats o análisis de código fuente, DeepSeek-OCR permitiría guardar el contexto antiguo en imágenes muy comprimidas y solo mantener la parte nueva en alta resolución. Así, los LLM pueden acceder a miles de páginas de información relevante usando una fracción de los recursos tradicionales.
Desafíos técnicos y respuesta de la comunidad
El despliegue en entornos de hardware como NVIDIA Spark ha demostrado tanto el potencial como los retos asociados. En pruebas relatadas por usuarios y desarrolladores independientes, se hace hincapié en la importancia de identificar la combinación adecuada de versiones de PyTorch y CUDA para conseguir que la aceleración por GPU funcione sin errores. Además, la integración en contenedores Docker y el uso de herramientas de desarrollo remoto (por ejemplo, monitorización desde VS Code en MacOS) está facilitando la adopción del sistema en entornos profesionales.
La comunidad destaca la necesidad de elegir bien los prompts, ajustar los scripts de inferencia y explotar al máximo la modularidad del modelo. Los múltiples scripts, guías de prompts y ejemplos de resultados compartidos ayudan a superar los obstáculos más frecuentes y ponen de relieve el enfoque abierto y transparente del proyecto DeepSeek.
Impacto y aplicaciones prácticas
DeepSeek-OCR abre la puerta a una nueva generación de aplicaciones de inteligencia artificial multimodal. Sus capacidades permiten:
- Automatización documental en empresas, con procesamiento masivo y eficiente de PDFs, contratos y facturas.
- Digitalización inteligente de archivos, preservando la estructura y contexto visual de documentos históricos.
- Herramientas de accesibilidad avanzadas para personas con discapacidad visual, gracias a la generación de descripciones contextuales precisas.
- Indexación avanzada de contenido multimedia para buscadores y sistemas de gestión documental.
- Visores interactivos que permiten consultar elementos específicos de una imagen mediante referencias espaciales y grounding.
- Consultas y análisis visual-texto en entornos LLM, mejorando la velocidad y la capacidad de respuesta frente a sistemas que dependen únicamente del texto plano.
Perspectivas de futuro y desarrollo abierto
Una de las mayores ventajas de DeepSeek-OCR es su enfoque open source y la transparencia en la publicación de pesos y arquitectura. A diferencia de otras grandes empresas que guardan sus avances como secreto industrial, DeepSeek pone a disposición de la comunidad su modelo y documentación, lo que facilita la experimentación, auditoría y expansión por parte de desarrolladores externos.
Este planteamiento abierto está acelerando la adopción y la investigación en compresión óptica de contextos. Se están explorando nuevas aplicaciones, como la inclusión de contextos visuales comprimidos en flujos de trabajo de LLM empresariales, la reducción del coste computacional en indexación masiva, y la creación de bancos de datos visuales comprimidos para aprendizaje incremental.
Este avance en la interacción entre imagen y texto en inteligencia artificial tiene el potencial de transformar múltiples industrias, gracias a su capacidad para comprimir, estructurar y transferir la información visual de manera eficiente y escalable.
